Many of us hear the YouTube videos whose voices are generated by AI, or even some of us use such APIs actively. But, you may wonder how good the public text-to-speech (TTS) APIs. It is actually a hard problem, even in the AI society. For such TTS evaluations, some groups use Word Error Rate (WER) or Character Error Rate (CER) or human preferences or random preferences ranking. The former is objective, but cannot measure small naturalness or quality errors. The latter cannot measure the deep aspects of voices.
Such measurement requires deep understanding in AI and human psychological aspect of evaluations, which is indeed a tedious and costly process. Here, Podonos provides a great value for such evaluations by utilizing a collaboration of our own AI models and human collective intelligence. It is simple and fast.
That being said, one big question is that which public TTS APIs (Eleven Labs, OpenAI HD, Resemble AI, Google Cloud, Play AI, AWS Polly) work great for US English generation. So we carefully designed an evaluation structure, executed a large scale evaluation. Here we are happy to show the detailed analysis report of the TTS APIs.
Voice Naturalness
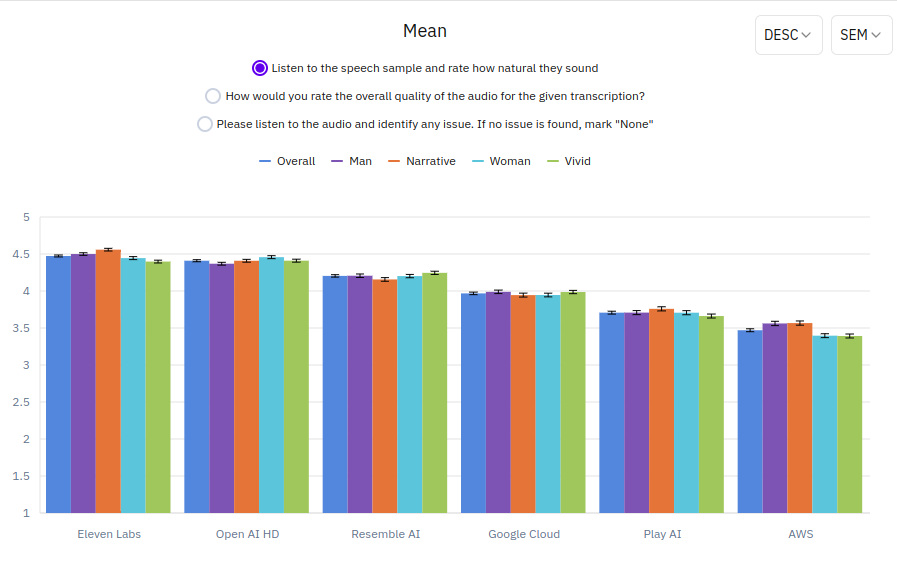
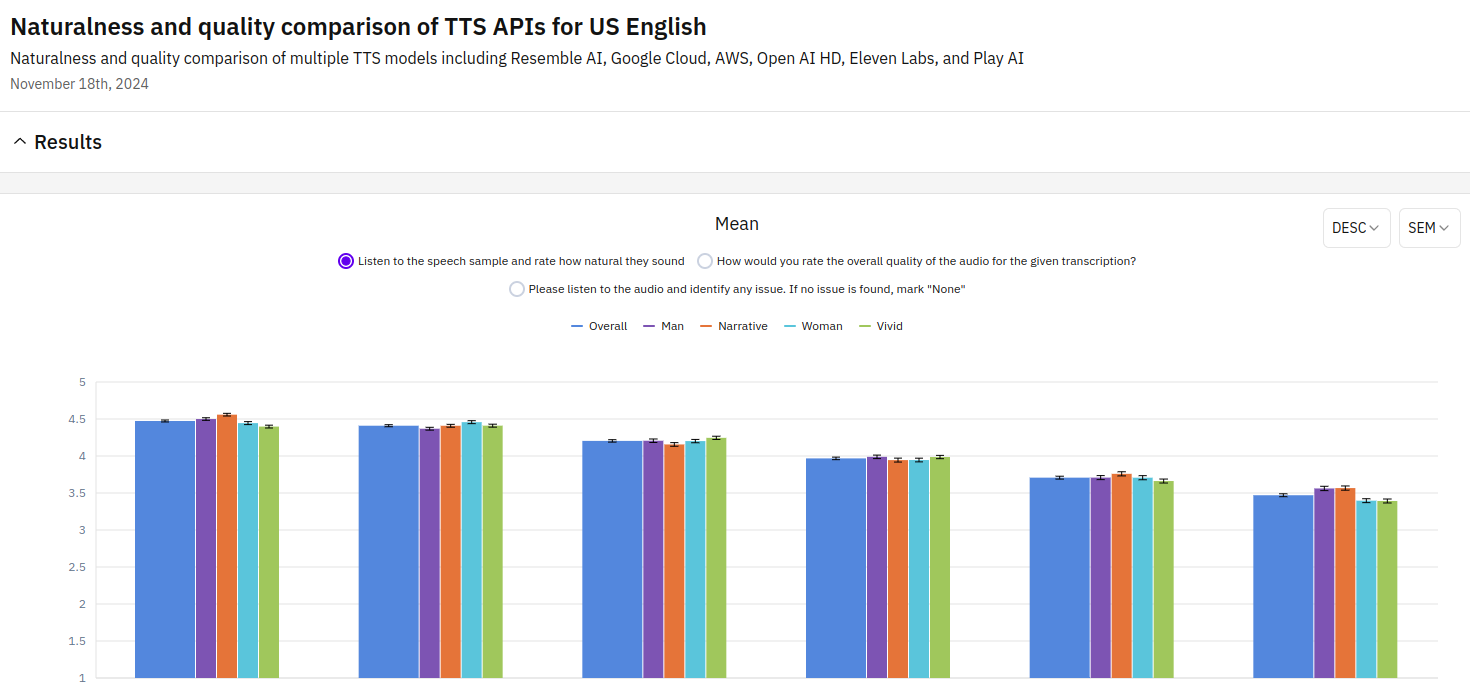
The naturalness is measured by asking “How natural they sound” in the scale of 1-5, where 1 is the most unnatural and 5 is the most natural. Among the 6 TTS models, the top one in terms of naturalness is the one by Eleven Labs, followed by OpenAI and Resemble AI. The differences among the top three are small, you cannot easily distinguish which better.
Here we need to see the details: two voice types (narrative vs vivid) and the gender types (woman vs man). For OpenAI, the woman’ voice is more natural than the man’s voice. For Resemble AI, their vivid voice sounds more natural than the narrative one.
Among the two popular cloud services, the TTS provided by Google Cloud is apparently better then the one by AWS. Especially, the gap between the man’s and the woman’s voice by AWS is noticeably large.
Voice Quality
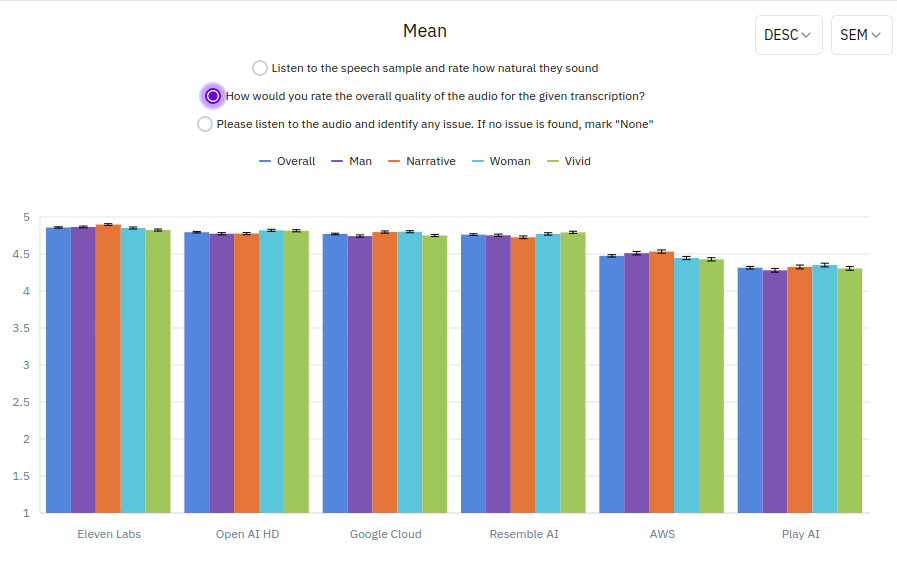
This section evaluates the quality of the generated voices, not the naturalness. It includes background noises, unexpected trembles, sudden volume changes, and so on. The top four TTS models (Eleven Labs, OpenAI, Google Cloud, Resemble AI) apparently show similar quality levels while the other two (AWS and PlayAI) show some noises. If you want to hear, you can go down to the comparison graph or the File section on the left panel.
Result: Detailed reasons
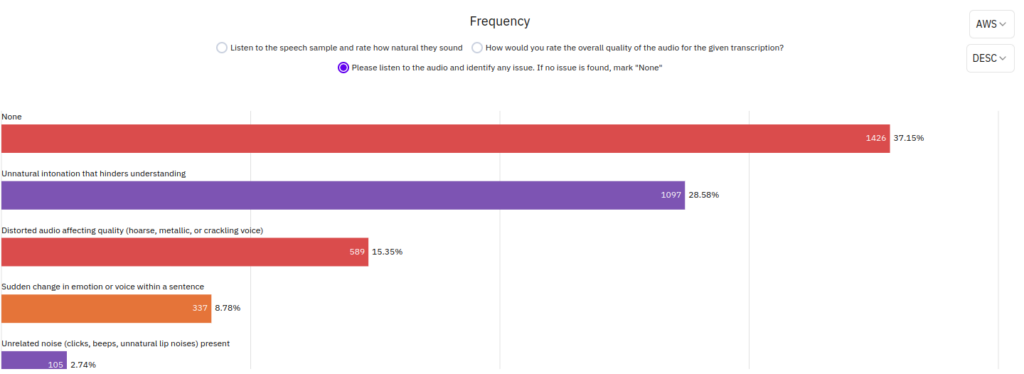
You may wonder why some models get lower scores than the others. The next section shows the counts and ratios of the rating reasons. Here is an example of AWS: 28.6% are marked with unnatural intonations, 8.8% are with sudden changes in the emotion. With these, you can figure out where to focus more on in the next model refinement stage.
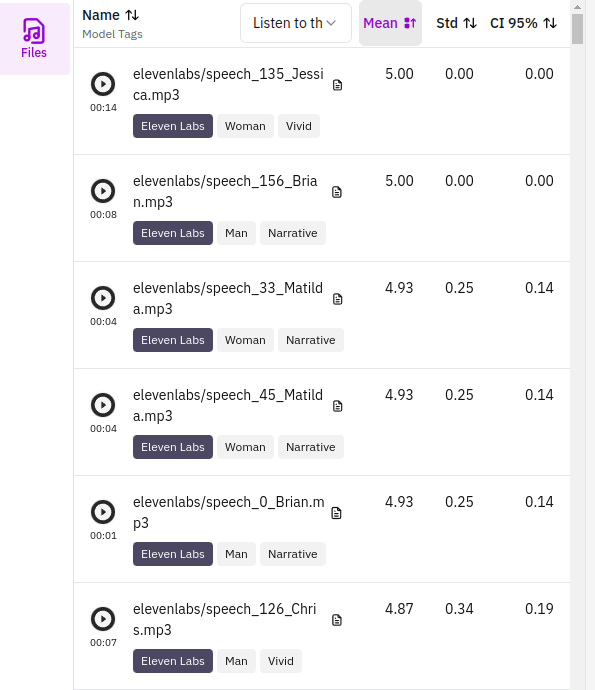
On the File section in the left panel, you can see the individual files, their models & tags, and the mean scores per each question. In addition, the files with the note icon have its transcript, even some of them are annotated with detailed reasons. So, you can find the detailed examples and reasons what TTS outputs degrade the performances.
Methodology
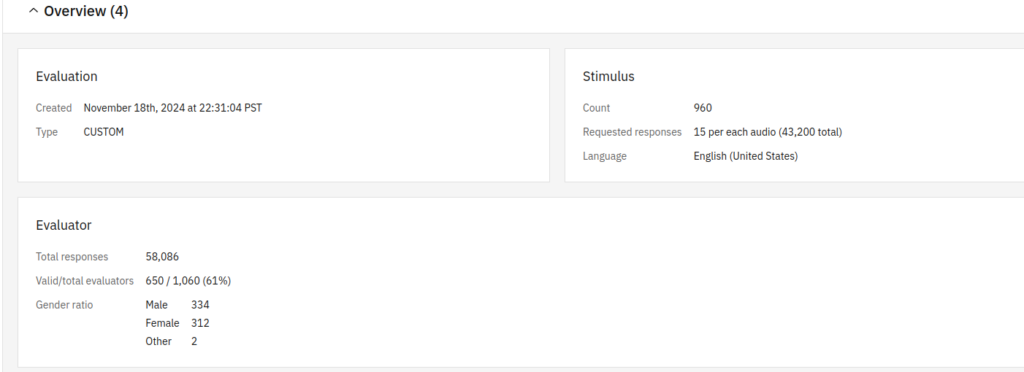
For this evaluation, we initially required 15 people per each query (one audio file & a question set), so we can get a statistically meaningful result for each audio file. You see the number 650 and 1060. The target number of evaluators are automatically calculated by considering their fatigue level. Some of the evaluators don’t have a good listening capability, some others were not wearing headphones. Such evaluators are disqualified and filled up with other evaluators, totaled to 1060.
In addition, we automatically added attention tests where the answer is known to us. If the evaluators pay reasonable attention, they can pass the tests. All of these processes are done automatically with all the background AI model inferences, the total time from the evaluation kickoff to the final report generation took only 12 hours. Yes, 12 hours with 1000 people.
But we should read carefully
Even though we carefully selected the models, the test data, and the evaluation structures, there might be unknown biases. And remember that the AI models are under active development, so the performances may be different in the next time.
In addition, this is for US English only. This evaluation doesn’t guarantee that the AI models would also perform well for other languages too.
Remaining Mystery
In this evaluation, we only covered 6 popular TTS models. As of 2024 Nov, you can find other 500 models in the public or academic domain. Most of the TTS models support more than 50 languages while only US English is evaluated in this report. We regularly evaluate multiple TTS models in the regional markets, which may be trained on the data specific to the target region. Next time, we will analyze the TTS models for non-English languages.